Data Collection & Labeling: The Foundation of Trusted AI
If you’ve rushed straight to model building without giving data collection and labeling the attention they deserve, you’re setting yourself—and your AI projects—up for disappointment. Accurate, well-structured data is the bedrock of reliable machine learning. In this post, we’ll dive into why labeling matters, the challenges of balancing quality and cost, the options for getting work done, and how to put rock-solid quality controls in place. By the end, you’ll understand how investing in precision labeling pays dividends in AI performance and business impact.
Key Takeaways
-
High-Quality Labels Drive Model Performance
Precisely annotated data is the foundation for accurate, reliable AI outputs. -
Balance Accuracy and Cost
Find the sweet spot between speed, budget, and label fidelity to maximize ROI. -
Select the Right Labeling Strategy
In-house, vendor, or hybrid—choose based on domain complexity, volume, and resources. -
Embed Continuous Quality Control
Use clear guidelines, periodic audits, and fast feedback loops to maintain labeling consistency. -
Treat Labeling as an Investment
View annotation not as overhead but as critical infrastructure that powers scalable, trusted AI.
Why AI Data Labeling Drives Model Accuracy
At its core, machine learning is pattern recognition: your algorithm learns from examples you feed it. If those examples are mislabeled, your model’s “lessons” are wrong. Consider a self-driving car trained on images where stop signs are sometimes tagged as speed-limit signs—it might literally drive right through a stop. Proper labeling ensures:
- Accurate Models
Correct labels teach algorithms the true relationships in the data, so predictions translate faithfully into real-world actions. - Efficiency in Development
Well-structured data short-circuits weeks of cleaning and backtracking, letting data scientists focus on refining models instead of chasing down inconsistent labels. - Long-Term Scalability
As your dataset grows, consistent labeling standards let you onboard new data without reinventing your workflow, so you keep momentum as your business and data volume expand.
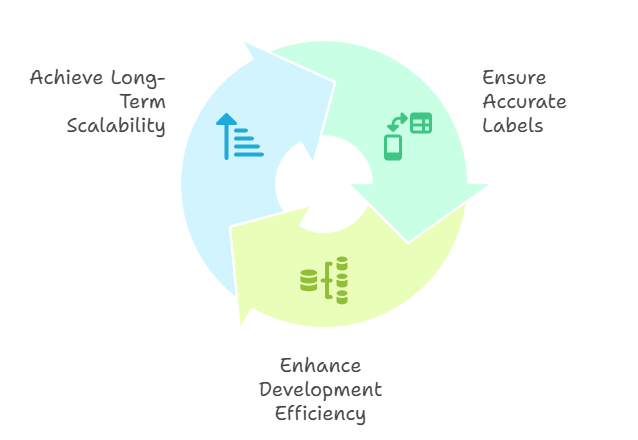
In short, no matter how advanced your algorithms, garbage in equals garbage out. Prioritizing data labeling from day one is non-negotiable if you want AI you can trust.
The Accuracy vs. Cost Dilemma
Achieving perfect labels across millions of records can be prohibitively expensive, yet cutting corners invites errors that undermine model performance. This tension plays out along three dimensions:
- Speed
Rushing to label large batches introduces mistakes—typos, inconsistent interpretations, even dropped examples—that ripple through your pipeline. - Cost
High-fidelity labeling by domain experts commands premium rates, quickly ballooning budgets when you have tens or hundreds of thousands of items to annotate. - Accuracy
Sacrifice too much quality and your AI’s precision plummets, forcing costly retraining and eroding stakeholder confidence in your efforts.
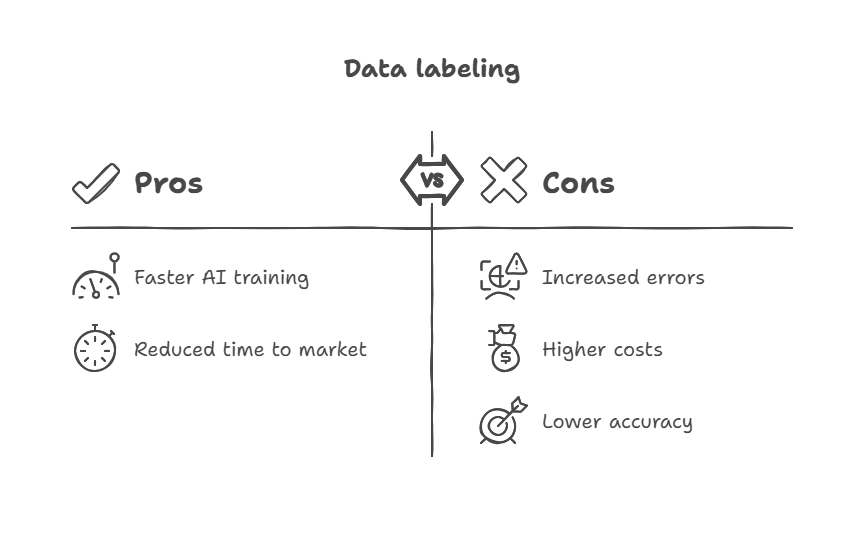
Finding the sweet spot requires thoughtful trade-offs. Smart teams tier their data: critical, high-value segments get expert review while simpler tasks can be crowdsourced or automated. That way, you protect your budget without sacrificing the core quality your models need.
AI Data Labeling Workforce Strategies
You have three main avenues to get your data labeled—and the right choice depends on your specific data complexity, budget, and timeline:
In-House Labeling
Leverage your own staff or dedicated internal annotators to capitalize on deep domain knowledge. An internal radiologist labeling medical images or a product specialist tagging feature categories will often produce the highest quality. The downside is ramp-up time—training requires both instructors and protected hours for labelers, pulling them away from other tasks.
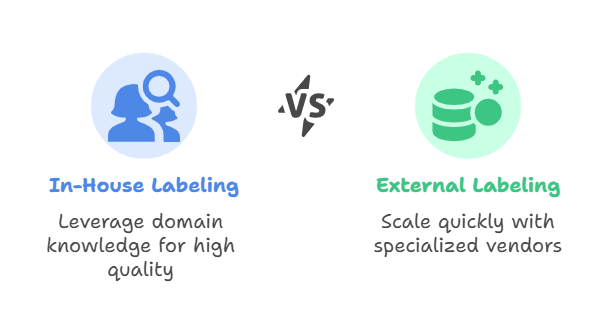
External Vendors & Platforms
Commercial annotation services and managed platforms scale rapidly, offering specialists trained on best practices, workflow tools, and built-in QA steps. You pay per item or per hour, but the streamlined processes and service-level guarantees often offset those costs—especially when you need to digest large volumes quickly.
Hybrid “Human-in-the-Loop”
Combine automated pre-labeling (using a preliminary model or rule-based system) with targeted human review. The machine handles repetitive bulk tasks, flagging only uncertain or high-impact examples for human attention. This approach blends speed, cost-efficiency, and accuracy, making it a favorite for organizations balancing tight timelines and quality requirements.
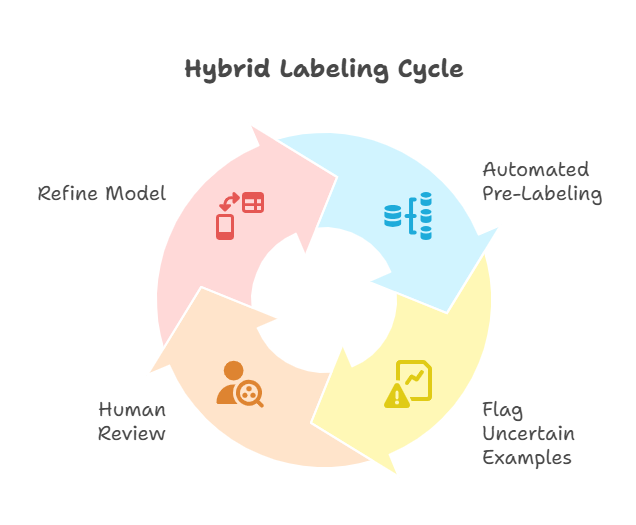
No single path is universally best—you might pilot all three to see which aligns to your data’s complexity, confidentiality needs, and budget constraints.
Ensuring Quality Control
Regardless of who or what does the initial labeling, you need a robust QA process to catch and correct errors before they poison your model’s learning. Effective quality control hinges on four pillars:
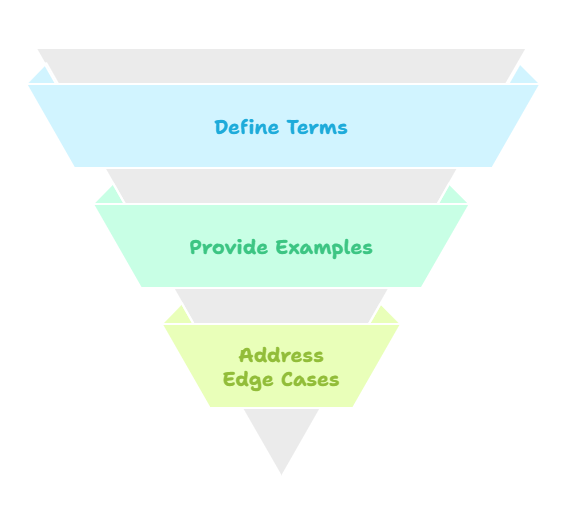
Clear, Detailed Guidelines
Invest time up front in a comprehensive labeling “playbook” with unambiguous definitions, positive and negative examples, and edge-case instructions. Well-crafted guidelines reduce guesswork and inter-annotator disagreement.
 Regular Audits
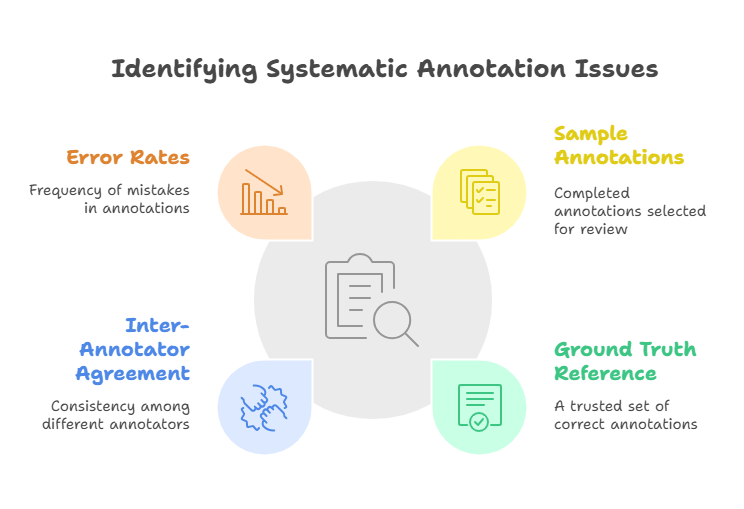
Regular Audits
Sample completed annotations and compare them against a trusted “ground truth” reference set. Measuring inter-annotator agreement and error rates pinpoints systematic issues—whether in understanding, tool misuse, or guideline gaps—that you can correct swiftly.
 Continuous Feedback Loops
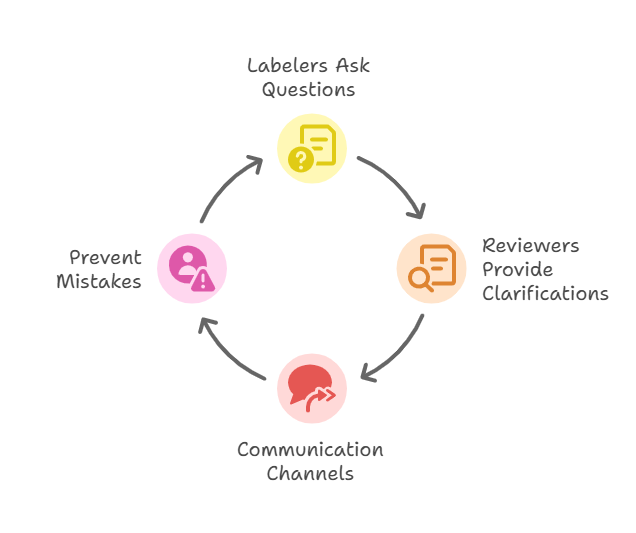
Continuous Feedback Loops
Build channels for labelers to ask questions and for reviewers to send clarifications back into the process. A dedicated Slack channel or an integrated tool-based comment system keeps communication tight and prevents repeated mistakes.
 Smart Tooling for Edge-Case Flagging
Smart Tooling for Edge-Case Flagging
Leverage labeling platforms that automatically surface low-confidence examples (either via model uncertainty scores or statistical outliers). By directing human attention where it matters most, you maximize the ROI of your review effort.
Quality control isn’t a one-and-done checkbox—it’s an ongoing commitment that ensures your data remains reliable as you scale.
Conclusion & Next Steps
Data labeling isn’t a perfunctory task—it’s the bedrock that determines whether your AI stands up in production or folds under pressure.
- Labeling drives accuracy. Even the most advanced algorithm can’t rescue mislabeled data.
- Balance precision and cost. Segment data by complexity and business impact so you allocate budget where it matters most.
- Choose the right delivery model. In-house, outsourced, or a hybrid approach—pick what aligns with your mission and iterate from there.
- Enforce rigorous QA. Clear guidelines, continuous audits, real-time feedback loops, and tooling for edge cases keep your labeling pipeline airtight.
Make that up-front investment in precision, and your models will pay you back with the reliability and performance the business expects.
Bonus Resources
- Data Labeling Best Practices Guide (Free Download)
A concise, step-by-step overview for creating, managing, and maintaining high-quality labels. - Customized Labeling Quote
With these tools and best practices, you’ll lay the groundwork for AI that’s not just powerful—but truly trustworthy.
Ready to turn raw data into AI fuel?
Download our Data Labeling Practices Guide and claim a free, no obligation consultation to map the fastest most cost-affective path to high quality labels for your next model.